|
|
Pandas是Python里非常有趣,有意思的模块。虽然翻译过来的意思是“熊猫”,但其实不是这样的。”Pandas“源于“Panel Data Analysis", 是将数据以二维数组的形式表达。其可以将复杂繁琐的数据进行清晰的整理,访问起来也特别的轻松。
Pandas的数据可以分为Series和Dataframe.
Series其实可以理解为List的升级版,如下:
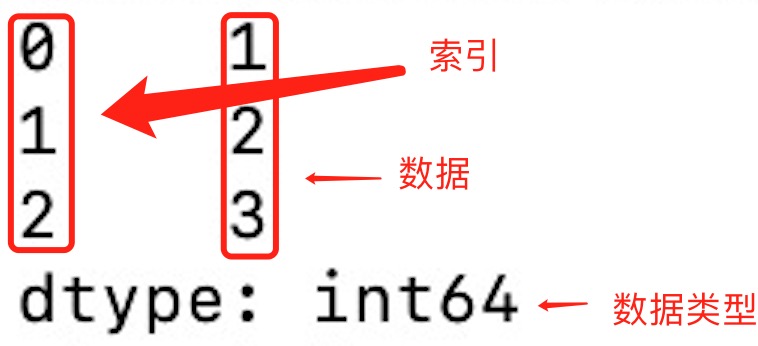
0,1,2是series的index,而1,2,3是数据本身。到了这一步,可能大家会有个问题:这series和List看起来一摸一样啊,到底有什么区别呢?
当然是有的。看完怎么生成series就知道了:import pandas as pd
obj2 = pd.Series([4, 7, -5, 3], index=['d', 'b', 'a', 'c'])
index在这里是可以自己修改的!就像一个自定义表格一样。
讲完了Series, 就是Dataframe了。Dataframe可以理解为好多个series放在一起,形成如Excel表格一般的二维数组。Dataframe的使用方法和用处有很多,本教程就会cover其中三种:制作Dataframe, 访问数据,形成excel表格。
制作Dataframe:
Dataframe的制作方法也是非常之多。个人认为最好用的是输入一个字典,其中key就是每一列的index,value就是所有column底下的数据形成的list。需要注意的是,Dataframe有着行和列两种index,让访问数据变得更加灵活。以下是创建Dataframe的例子:
这样的数据当然也可以用来访问和篡改。如果想要访问一列,拿“pop"来举例:
frame['pop']即可访问。import pandas as pd
data = {
'state': ['Ohio', 'Ohio', 'Ohio', 'Nevada', 'Nevada', 'Nevada'],
'year': [2000, 2001, 2002, 2001, 2002, 2003],
'pop': [1.5, 1.7, 3.6, 2.4, 2.9, 3.2]
}
frame = pd.DataFrame(data)
print(frame)
如果想提取数据或者篡改,可以用iloc或者loc. iloc语句无视index的名字,直接访问数字index(比如需要访问最后十行数据,那不管index有没有特殊名字,直接[-10:])
以下是用iloc和loc访问的案例:
<div class="blockcode"><blockquote>one two three four
Ohio 0 1 2 3
Colorado 4 5 6 7
Utah 8 9 10 11
New York 12 13 14 15
data.loc['Colorado', ['two', 'three']]
out: two 5
three 6
Name: Colorado, dtype: int64
data.iloc[[1, 2], [3, 0, 1]]
out: four one two
Colorado 7 4 5
Utah 11 8 9
(tip: iloc 和loc还有很多各种各样的使用方式!不像传统语法,其格式并不是固定的。感兴趣的可以去博客,谷歌查一下!)
讲了这么多语法,是时候讲一些实用的东西了。Dataframe还有一个好处,就是可以从Excel直接导入,也可以导出成xlsx格式的文件。其甚至可以用来生成Matplotlib的图表!(请期待下次更新Matplotlib教程,也会提到Dataframe。这下大家意识到学好Pandas的重要性了吧 )。 )。
好。Excel的格式转换其实特别简单,一句代码就行:
导入:
df = pd.read_excel('example.xlsx')
导出:
df.to_excel('example.xlsx', index = )
index 默认为True,需要row index不写也行。但想要输出的excel文件不显示row index,就写index = False.
读完这篇文章,你也算是入门DataFrame了。如果有任何问题或者探讨话题,可以在评论区里留言,小编绝对会看的!
下期内容为Matplotlib教程,敬请期待!
|
|


 发表于 5-9-2025 20:29:25
发表于 5-9-2025 20:29:25
